29 October 2018
How to Learn Cross-Lingual Mappings Without Supervision
To accurately translate between languages, one typically requires a dictionary. This principle applies to machines as well. Currently, these dictionaries take the form of linear mappings, transitioning from continuous word representations—commonly known as word embeddings—in one language to equivalent word representations in another. A fundamental initial step in learning these mappings is to acquire word embeddings for both the source and target languages. For those interested in understanding how to learn these monolingual embeddings, further information is available on word2vec, the most commonly used technique in this area.
Our focus here is on exploring the process of learning cross-lingual mappings without supervision. We aim to do this by summarising various research papers on the subject, presenting the concepts in an accessible manner, free from complex equations!
There is a linear mapping for every language pair
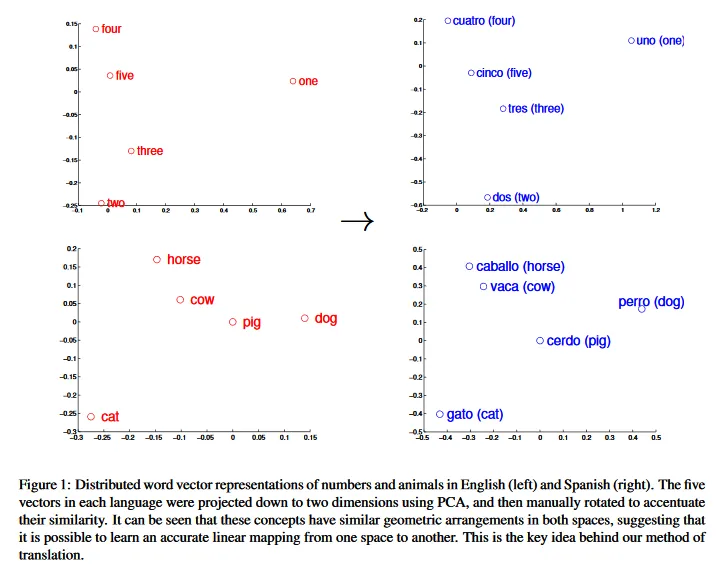
In one of their paper, Mikolov et al., 2013a discovered that word embeddings “are surprisingly good at capturing syntactic and semantic regularities in language” so that we can observe, with simple algebraic operations, relationships like:
Given such regularities, it's reasonable to propose the existence of a linear function capable of mapping one set of word embeddings (i.e., a vector space) to another. Indeed Mikolov et al., 2013b observed that this mapping function is, in fact, linear. Further research indicated that more complex functions do not significantly improve the mapping. However, the challenge lies in learning all the parameters of this linear function.
Challenges with supervised approaches
Consider the task of mapping English words to their Spanish equivalents. Ideally, we would have a function such that:
Using a bilingual lexicon containing several thousand word pairs, as detailed in Mikolov et al., 2013b, we can readily achieve this by learning the parameters through supervised methods. This process involves minimising the distance between the mapped vectors and the correct vectors in the lexicon.
However, these supervised methods necessitate bilingual lexicons, which are not always readily available for a vast array of language pairs globally. Moreover, constructing these lexicons is often a prohibitively expensive and laborious task. Consider, for example, the challenge of acquiring data for a Swahili-Chinese language pair.
Due to these constraints, researchers worldwide have shifted their focus towards developing unsupervised approaches for learning these linear functions. In this article, we will explore three cutting-edge unsupervised methods.
1 — Adversarial approach
This method employs the renowned Generative Adversarial Network (GAN) architecture to deduce the linear mapping. The initial convincing application of this concept was presented by Zhang et al. (2017), whose results, though intriguing, did not quite match the efficacy of supervised approaches. Subsequently, Conneau et al. (2017) introduced several refinements to the adversarial model, significantly enhancing its performance.
Generative adversarial network
The GAN architecture, pioneered by Goodfellow et al. (2014), revolves around two components: a generator and a discriminator. The generator's role is to deceive the discriminator, which, in turn, aims to excel at classification or regression tasks. This dynamic sets up an adversarial game. A notable challenge with this architecture is its stability, making it tricky to train effectively. For a deeper insight into this issue, consider exploring this detailed yet technical article.
In the context of this method, the generator's weights function as the linear mapping.
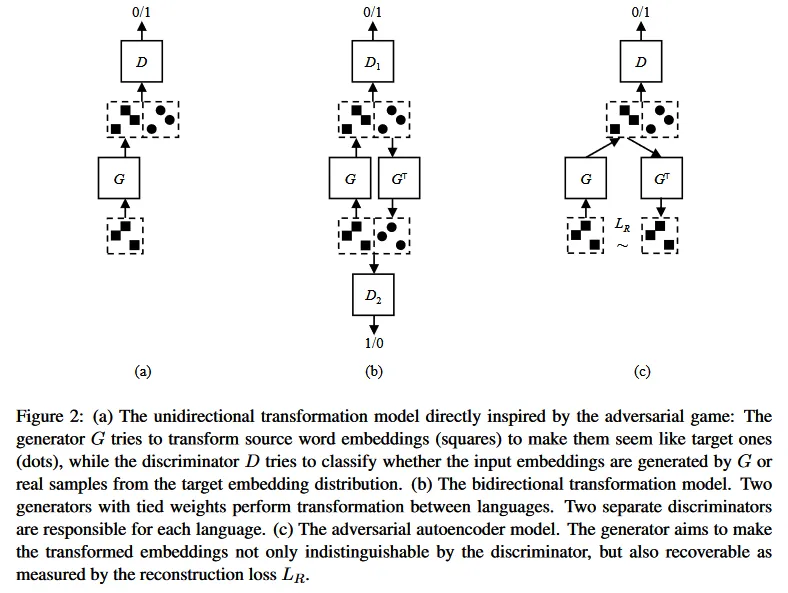
Zhang et al. (2017) introduced three distinct methods, with the third one, termed the adversarial autoencoder, standing out in terms of performance. This approach operates on the principle that after the generator transforms a source word embedding into a target language representation , it should be possible to reconstruct the original source word embedding by mapping it back with the transpose of . In simpler terms, if you can translate from English to Spanish, you should theoretically be able to reverse the process using the same mapping.
However, this operation incurs a loss, which is then incorporated into the loss function of the generator. The goal is to adjust the generator to minimise this loss.
Despite this, the stability issue inherent in GANs persists. As a result, the model does not always converge to an optimal solution. The authors addressed this by selecting model parameters during training that exhibit a significant drop in the generator's loss, indicating a potential local minimum.
Yet, the story of the adversarial approach doesn't end here. Conneau et al. (2017) developed an improved and more stable method, revitalizing the potential of this approach.
Refinement and CSLS
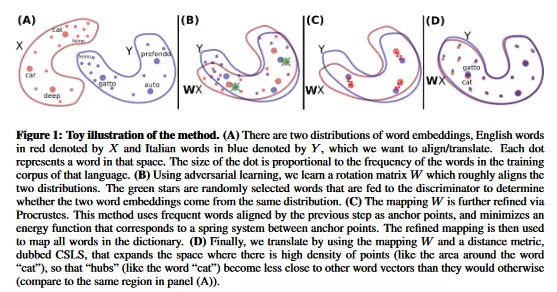
The first notable improvement involves refinement by selecting only the most frequent words as anchor points for mapping inference. These anchors serve as reference points, facilitating linear transformations (e.g., rotations) until the word embeddings of the two languages nearly overlap.
The second advancement is the introduction of Cross-Domain Similarity Local Scaling (CSLS). This technique refines the metric for comparing word embeddings, enhancing the likelihood that the nearest neighbour of a source word in the target language also recognises the source word as its closest neighbour.
However, this isn't as straightforward as it sounds. For instance, if "Ford" is the nearest neighbour of "car", it doesn’t automatically mean "car" is the nearest neighbour of "Ford". Moreover, their method cannot utilise any cross-validation criteria (i.e., parallel data) because it is inherently unsupervised. Despite this challenge, they successfully developed a similarity measure so effective that it became a standard in subsequent research. For a detailed mathematical explanation of this metric, refer to their paper.
Some results
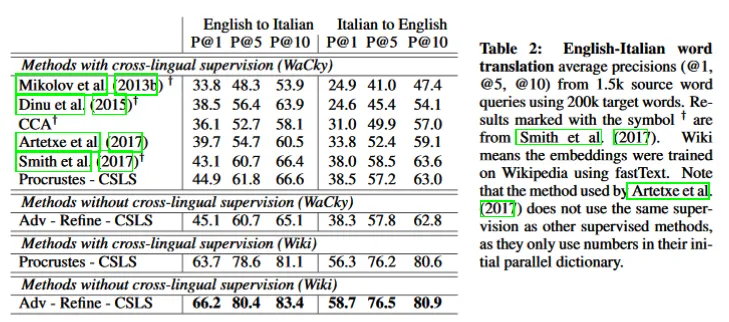
Table 2 in Conneau et al.’s paper demonstrates that the Adversarial — Refined — CSLS method surpasses supervised approaches on the Wikipedia dataset. However, the validity of this evaluation method has been questioned. Critics point out that the Wikipedia dataset might contain comparable corpora in different languages, implying the indirect presence of parallel data.
2 — Self-Learning approach
The approach devised by Artetxe et al. (2018) sets itself apart with a distinct objective compared to other methods. Unlike the supervised and adversarial approaches, which focus on directly mapping a word from a source language to its counterpart in a target language, Artetxe et al.'s method aims to create a shared linguistic space. Within this shared space, both sets of word embeddings are mapped using their respective functions. The team then constructs a dictionary through an iterative self-learning algorithm.
A key advantage of this method, as claimed by the authors, is its realism and the ability to generalize effectively across linguistically distant pairs, such as English and Finnish. This is an area where adversarial methods have historically struggled to deliver satisfactory results.
The four sequential steps
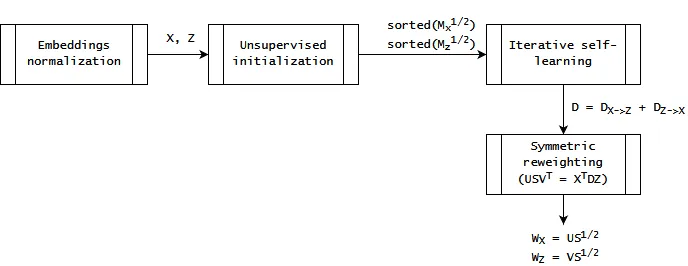
The central challenge addressed by the researchers in this paper is the initialization of a dictionary without parallel data, aiming to approach the optimal solution as closely as possible. This initialization is crucial as it sets the stage for their iterative algorithm to efficiently find a local optimum, which ideally coincides with the global optimum. A random initialization could lead the algorithm to an undesirable local optimum, resulting in poor performance. Therefore, achieving an effective unsupervised initialization is a critical step.
Before this initialization, however, comes the step of embeddings normalization. This process aims to simplify the measure of similarity between word embedding matrices. It ensures that "the dot product of any two embeddings is equivalent to their cosine similarity."
After the normalization, the unsupervised initialization of the dictionary is predicated on the hypothesis that equivalent words in different languages share similar similarity distributions. For instance, “bulldog” should be as closely related to “dog” in English as “bouledogue” is to “chien” in French. Leveraging this assumption, they construct an initial dictionary that significantly outperforms random chance.
But this nascent dictionary isn't directly used to fuel the self-learning algorithm. Several enhancements are necessary to optimize its efficacy: stochastic dictionary induction (random selection of dictionary entries), frequency-based vocabulary cutoff (focusing on the most frequent words), CSLS retrieval (as employed by Conneau et al.), and bidirectional dictionary induction (combining English-to-French and French-to-English dictionaries).
With these improvements, the self-learning algorithm becomes more robust, ready to commence its task. The algorithm works by first maximizing the similarities of the two mappings with the dictionary, then updating the dictionary to better align with these mappings.
The final step involves a reweighting process (detailed in their paper), which significantly enhances the quality of the dictionary. This reweighting adjusts the values to make them more 'useful', contributing to the overall effectiveness of the method.
Some results
The efficacy of the model is evaluated using a word translation task, which involves determining the most probable translation of a given word from a source language into a target language.
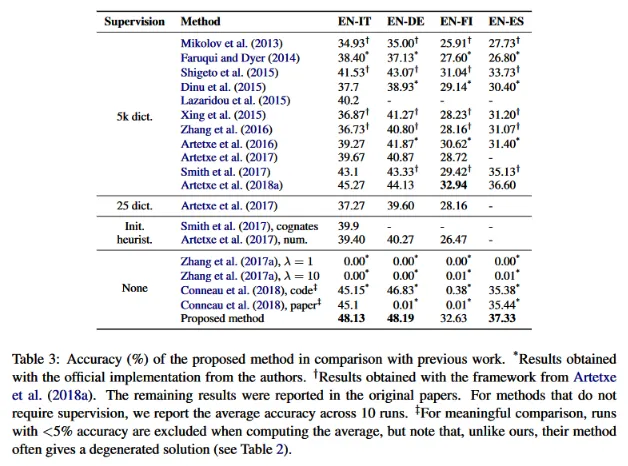
Table 3 from Artetxe et al.'s paper demonstrates that their method, despite being unsupervised, surpasses previous supervised methods in word translation tasks. It's important to note that the accuracy reported in the table is equivalent to precision at 1 (p@1).
An additional insight from the paper is the superior performance of this method compared to adversarial approaches, especially when dealing with more challenging datasets. In some instances, adversarial methods fail entirely, highlighting the robustness and realism of the self-learning model.
3 — Shared LSTM approach
In machine learning, the goal is often to achieve remarkable results with minimal data. The paper by Wada and Iwata (2018) claims to advance this objective, achieving state-of-the-art results using only thousands of monolingual sentences. Their approach is notably distinct from others in the field.
They introduced a bidirectional LSTM (Long Short-Term Memory) architecture that utilizes both shared parameters across multiple languages and unique separate parameters for each individual language. Unlike supervised and other unsupervised methods that rely on pre-computed word embeddings, Wada and Iwata’s approach concurrently calculates these embeddings alongside the cross-lingual mappings.
Long short-term memory
Recurrent Neural Networks (RNNs), with LSTM as a key variant, are designed to identify patterns in sequences, such as sentences in language or notes in music. RNN cells are often described as having “memory,” as each cell's input includes the output of its predecessor.
However, a limitation of RNNs is their focus on preceding information, often leading to negligible impact from more distant cells. To address this, the use of bidirectional networks is employed. This involves doubling the number of cells to create both a forward and a backward RNN. At any given position , this setup calculates hidden states using information from both the right (forward) and the left (backward), combining these values to form a more comprehensive understanding.
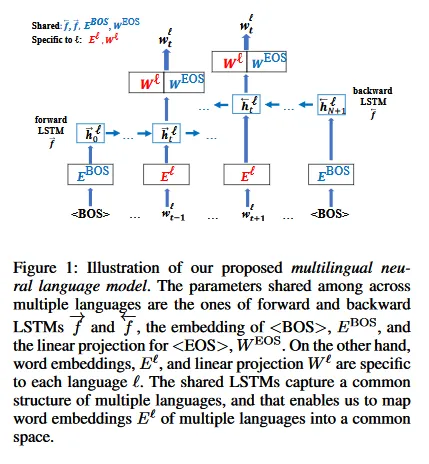
Multilingual neural language models
This method focuses on “obtaining cross-lingual embeddings by capturing a common structure among multiple languages.” For instance, Latin languages such as Spanish, French, and Italian often share similar structures, including word order rules like subject-verb-object. The proposed model leverages these shared linguistic patterns through the neural network's shared parameters.
The network is trained by maximizing log-likelihood in both directions, with probabilities calculated using a traditional softmax function applied to the word embeddings. It's noteworthy that while the hidden states are language-specific, the LSTM functions themselves are not.
Interestingly, this approach yields word embeddings but does not directly provide translations or mappings. For translation purposes, the embeddings are aligned based on similarity distributions. Once again, the CSLS technique from Conneau et al. (2017) is employed to retrieve translations in the target language. Practically, this involves matching a source language word vector with the most similar target language vector, incorporating adjustments via CSLS.
Some results
The evaluation of the model is a bit different than a word translation task. It’s a word alignement task: given a list of words in a source language and a target language, the task is to find a one-to-one correspondance between these words.
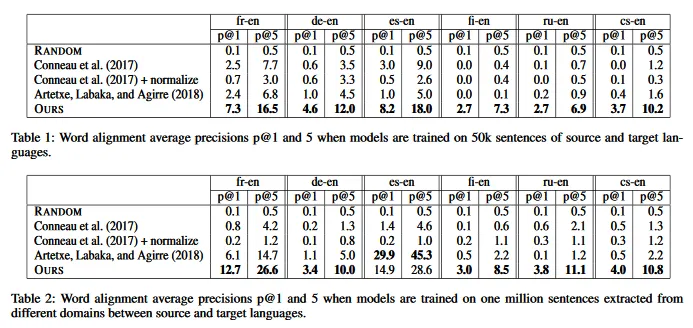
Table 1 clearly demonstrates that, even with limited data from similar domains (such as Wikipedia), their model surpasses adversarial and self-learning methods. However, this similarity in data sources raises concerns about overfitting to common structures and potentially limiting generalizability to data from varied sources.
Final word
The ability to translate words between languages without relying on parallel data is an extraordinary feat with wide-ranging global benefits. We can anticipate the evolution of these techniques for sentence translation, even for linguistically distant pairs, still without parallel data. Undoubtedly, researchers worldwide are advancing these efforts, and we eagerly await the fruits of their labour.
I hope you found this post enlightening!
Note
This post orginally was first published on Medium, and was republished here with reformulations and grammar corrections.